After collecting a dataset, it is time to train the object detection model. I am using the YOLO11 model from Ultralytics. The model is already pre-trained on the large COCO dataset and has already learned generic image features. Therefore, fine-tuning only requires a much smaller dataset to learn new classes.
Goal
Train a first prototype to get a feel of the performance.
-How good does the boat and buoy detection work with actual images and videos taken from the sailboat?
Challenges
One challenge in the domain of sailing is the different and most of the times not optimal lighting:
- Reflections: Sunlight reflections on the ocean (glare) can saturate parts of the image.
- Low contrast: Haze, fog or cloudy days result in soft edges and low contrast.
- Variable illumination: Lighting intensity varies greatly during the day and with the weather.
Another challenge is the small size of the objects:
- Objects are often far away with few pixels.
- Buoys are small and hard to distinguish from the background or the ocean.

Hardly visible buoy on the horizon
Training
Hardware
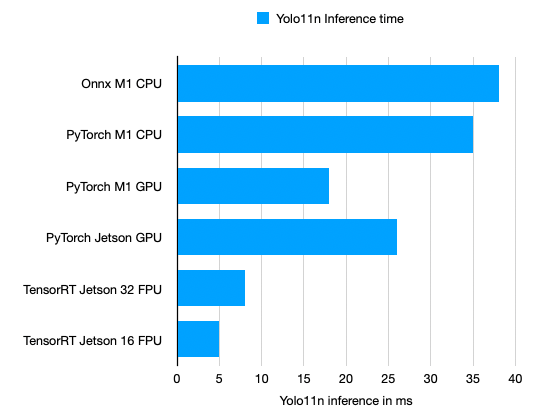
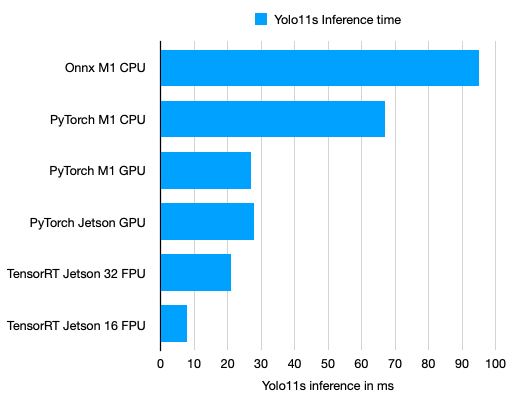
The YOLO11 model is trained locally on the NVIDIA Jetson Orin Nano. The GPU computing power is sufficient for a reasonable training time in the range of several hours. However, the memory is limited to 8 GB. For the YOLO11 small model, it is only possible to train with a maximum batch size of 3.
Parameters
- Low learning rate = 0.001: To preserve pretrained features and prevent catastrophic forgetting
- Starting with 50 epochs for first test
- Increased to 500 epochs in a second run
Result
Test on real videos
- Buoy detection exceeds expectations: Reliable detection even in difficult lighting and with small object size
- Boat detection is not forgotten: No catastrophic forgetting of already trained boat detection

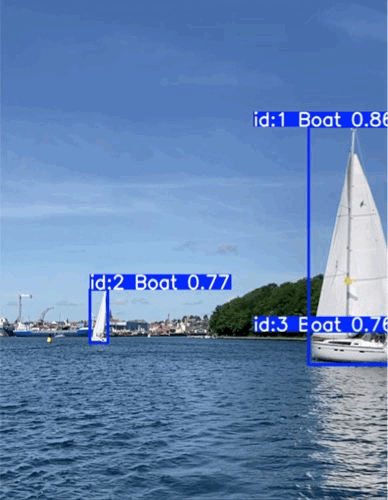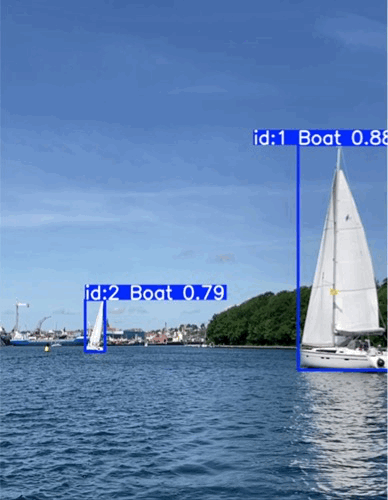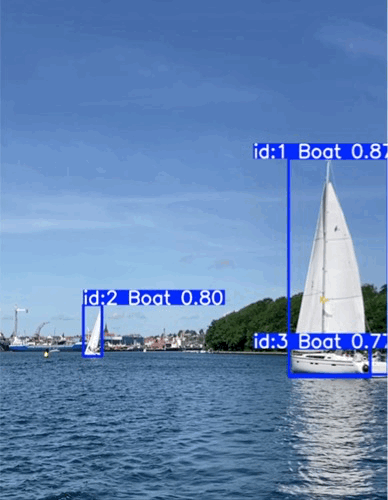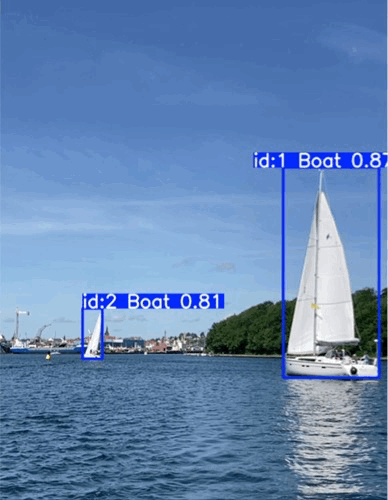
Stable detection of a buoy and sailboats
Metrics
This is just a quick look at the training metrics:
- The metrics such as box loss and mean average precision (mAP) flatten out after about 100 epochs
- The confusion matrix shows that boats and the background are often misclassified. This will need to be looked at more closely when I have better data for training.
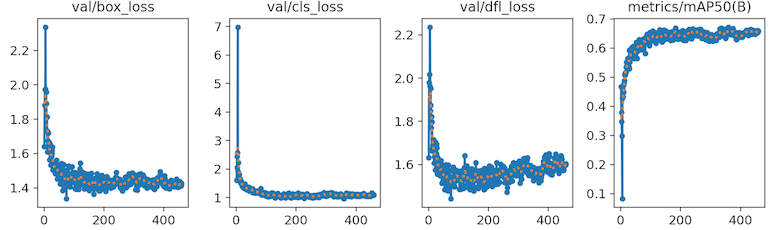
Metrics do not improve with more epochs
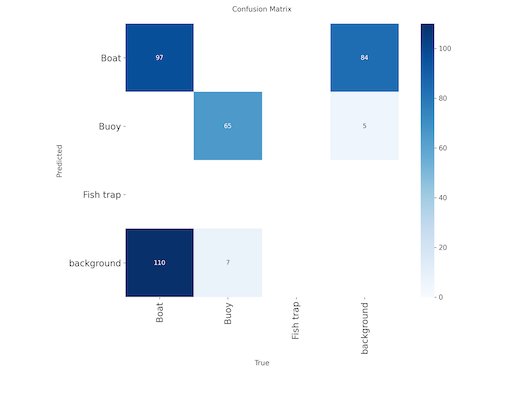
Boats and background misclassified
Outlook
In the next steps I will need to collect more domain specific data. The domains main characteristics:
- Sailboat perspective: Objects are usually small and on the horizon with a lot of water between.
- Varying and often poor lighting of the images.
- Varying background: When sailing into the open ocean, the background is uniform. When sailing towards land the background is noisy.
Next steps:
- Experimenting with hyperparameters such as batch size, learning rate and image augmentations.
- Evaluating model performance on a test set that represents the domain well.
- Setting up automated model training and performance monitoring (MLOps).